
Over the past year, we’ve been building some web apps in React that talk to our customers’ FileMaker servers and to Google’s Cloud Firestore database. As part of that, we’ve begun working with Google’s flavor of FaaS (Function as a Service), Firebase Cloud Functions. Cloud Functions, along with AWS Lamba and Microsoft’s Azure Functions, are part of a growing trend towards serverless architecture. The commonly cited advantages to utilizing Cloud Functions over server-based functions are typically:
- Zero maintenance: No servers to spin up, no infrastructure to deploy
- Scalable: Google will handle scaling up automatically
- Pay as you go: You will be billed only when the function runs, rather than having to maintain a server at all times
In addition, you’ll often hear that Cloud Functions have the advantage of being “event-driven,” meaning they can subscribe to events across a suite of cloud services and trigger based on those changes. This is true, but it’s not unique to Cloud Functions. One web app we’re building here, Datapage, relies on server-based, event-triggered functions to send updates to a FileMaker server based on changes in Firestore, and those functions are working just fine.
If these were the only advantages of Cloud Functions, there isn’t much of a case for us to use them. We already operate and maintain a server for Datapage, and we aren’t receiving so many peak requests (yet) that we’d be in danger of overwhelming that server. So why have we begun a foray into FaaS? There are subtle, less discussed advantages to Cloud Functions that were central to our decision to give them a try.

Less Configuration
Our first candidate problem for Cloud Functions was making regular backups of our production Cloud Firestore database. Google provides functions to export all of the database’s collections to a Cloud Storage bucket, insuring us against overwriting production data. We could handle this with the Google Cloud SDK and a cron job on our server, but that would require configuring credentials, environment variables, and maintaining the job.
At SeedCode, we aim to have new servers up and running within 10 minutes should our currently running production server encounter an unresolvable issue. If we were maintaining a cron job using the Google Cloud SDK, we’d have to install, initialize, configure, and authorize the SDK every time we spin up a new production server. This would significantly increase the complexity of our server initialization process, which we aim to keep as simple as possible. The last time you want to be debugging your init script is during a server outage.
Instead, we used a Cloud Function for this job. We have only one configuration step: our default GCP (Google Cloud Projects) user needs the right role to access our backup bucket. After that, we can deploy a function that utilizes Cloud Scheduler to run once every 24 hours, exporting our collections to Cloud Storage. If you weren’t counting, that’s four separate cloud services: Firestore, Storage, Functions, and Scheduler, all working together in harmony with a single configuration step which we will only have to make once.
Fewer Links in the Chain
We had another excellent candidate for Cloud Functions arise shortly after we began utilizing them for automated backups. As part of the in-app notifications we built for Datapage, we gave users the ability to mark subsets of their unread notifications as read. This is a potentially expensive operation: it requires first querying for unread notifications within the specified timeframe, then updating all of them with a new status. We could do this client-side with Firestore, but what if a user has hundreds or even thousands of unread notifications?
Instead of handling this client-side, we can do it in a Cloud Function. The user’s device won’t have to send out dozens of batched updates. The client will only send a single request to the callable Cloud Function, and the function will handle the rest, reading and writing within Google’s platform, with its superior networking. Since we are designing this app with plans to take it mobile in the future, we’re doing ourselves a favor by limiting expensive operations client-side.
Additionally, by not executing this function on our server, we are limiting links in the chain. Our database and function will run together on Google’s infrastructure, so we won’t need to pull down a large query onto our server and then send our updates back up. Instead of client -> Google -> server -> Google, we’re going client -> Google. Are the performance gains real? Maybe, but that’s a discussion for another article. For now, it’s enough to appreciate the reduced complexity.
Logging Google Cloud Functions
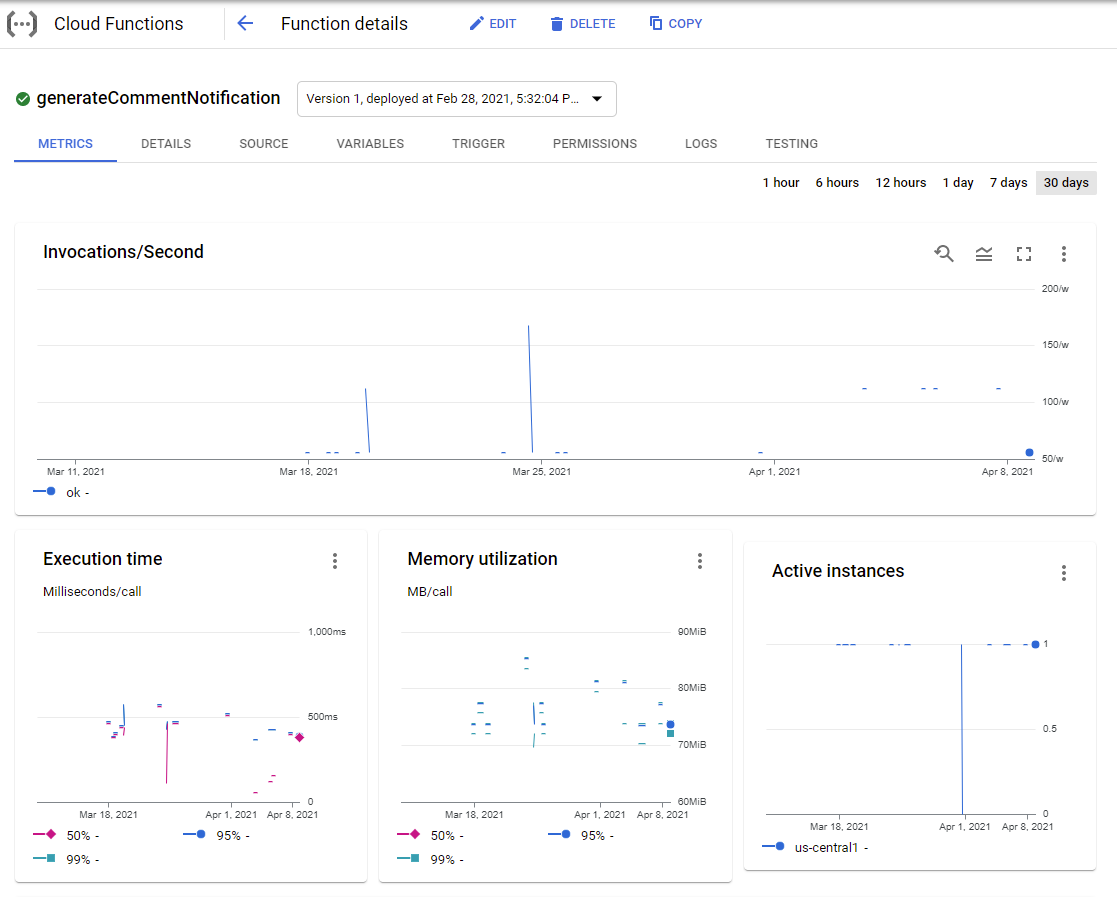
A severely underrated feature of Cloud Functions is Google’s excellent suite of logging tools. Want to know if the execution time of your function is going up? Want to use full-text search to find a specific error by timeframe? Don’t want to cross-reference your version control with your error log and wish you could just see which function invocation happened on which version of your app? It’s all here, and it’s all accessible through a secure web UI. Third-party server logging libraries with parity with these features do exist, but Google’s requires zero setup.
Beyond Our Use Cases
There’s a lot more here that we simply don’t yet have a use for: leveraging Google’s machine learning APIs, handling exceptionally CPU-intensive tasks, and integrating with 3rd party APIs. However, we have found that there’s enough of an argument to deploy some of our functions into the cloud anyway. We have no plans to move to a completely serverless architecture. Still, some aspects of serverless make sense, even if you’re already going to the trouble to maintain a server yourself.
Postscript: Vendor Lock-In
Dependence on a single company’s products and infrastructure is a major commitment. But when it comes to Cloud Functions, Google has taken steps to mitigate that concern by introducing the Functions Framework. FF allows Cloud Functions to become portable using containers and a set of open-source libraries. Moving your functions from the cloud down onto a server you manage yourself is now possible and will go a long way towards making the jump to Google’s Cloud Functions more inviting.

1 Comment
Sounds very cool… thanks for the article.